Mythos oder Wahrheit – die Rolle des Crawl Budget in der Suchmaschinenoptimierung
Die SEO-Welt ist voller Mythen oder zu mindestens Halb- und Viertelwahrheiten. Immer wieder wird diskutiert, ob das sogenannte „Crawl Budget“ dazu gehört. Mit diesem schönen Zungenbrecher verbindet sich die Frage, ob es beim Crawling durch den Googlebot Faktoren gibt, die Umfang und Qualität des Crawlingprozesses beeinflussen. Doch spielt Crawl Budget überhaupt eine Rolle für Sichtbarkeit und Rankings? Was am Crawl Budget dran ist, erfahren Sie in diesem Beitrag.
[text-blocks id=“2785″ slug=“kommentar-und-nachricht“]

To crawl or not to crawl – für Google keine Frage?
Sicher weiß (fast) jeder, der aktiv Online Marketing betreibt, was Crawling bedeutet. Google –aber auch andere Suchmaschinen- und Toolanbieter wie etwa Ryte führen einen automatisierten und systematischen Abruf von zu einer Domain gehörenden Webpages durch, analysieren, bewerten und indexieren diese. Crawling wird häufig mit dem Krabbeln einer Spinne verglichen, deshalb wird der Google „Crawler“ auch als „Spider“ bezeichnet. Effektives Crawling ist nach der Registrierung einer Website bei Google die entscheidende Grundlage für die Präsenz in der Suchmaschine und gute Rankings. Bleibt das Crawling aus, erfolgt verzögert oder eingeschränkt, dann können Optimierungen nicht oder nur verspätet von Google registriert werden. Doch wie häufig crawlt Google überhaupt? Googles Antwort lautet (typisch Google) „Wir crawlen genau mit der richtigen Häufigkeit“ und „macht euch keine Sorgen über das Crawl Budget.“
Der Googlebot – „a good citizen of the web“
Die Frage nach Häufigkeit und Umfang des Crawling erschließt sich aus der Intention Googles. Diese ist, alle Informationen der Welt zugänglich zu machen. Das funktioniert natürlich nur, wenn alle neuen Informationen zeitnah nach der Veröffentlichung erfasst werden. Zur Aktualität gehört aber auch, dass gelöschte Seiten bei Google aus dem Index entfernt werden, so dass sie in der Suche nicht mehr angezeigt werden.
Damit also eine einzelne Website oder ein Onlineshop bei Google stets aktuell und vollständig abgebildet werden können, ist Zeitpunkt und Umfang des Crawling wichtig. Der Umfang und die Häufigkeit des Crawling wird durch das sogenannte Crawl Budget gemessen. Das Crawl Budget wiederum ergibt sich aus der Crawl Rate und dem Crawl Bedarf. Google selbst erklärt die Begriffe und Zusammenhänge sehr anschaulich in diesem Beitrag.
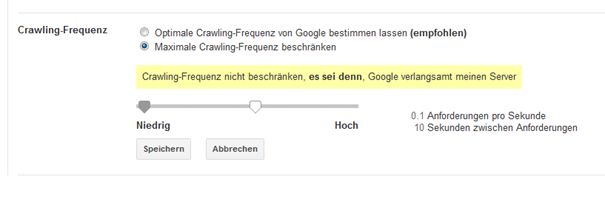
Danach ist die Crawl Rate schlicht die Anzahl der Seitenabrufe pro Sekunde. Reagiert ein Server schnell und problemlos auf die Anfragen des Googlebots, ist die Crawl Rate und damit auch die Crawlability (die gelegentlich auch Crawl Health genannt wird) sehr gut. Kommt es zu Verzögerungen, weil der Server verlangsamt wird, dann nimmt das Crawl Budget entsprechend ab. Die Crawl Rate kann übrigens über die Search Console auch von den Webmastern reduziert werden. Das kann dann Sinn machen, wenn man bei großen Seiten mit vielen Abrufen vermeiden will, dass es zu einer Verlangsamung aller Zugriffe, also auch der der Nutzer kommt. Zur Anpassung der Crawl Rate in der Search Console geht man auf die Property-Einstellung (die sich hinter dem Zahnrad-Symbol verbergen) und wählt dort die Website Einstellungen. Dort kann die Crawl Rate wie folgt angepasst werden:
Neben der Crawl Rate ist der Crawl Bedarf der zweite zentrale Faktor für das Crawling. Auf der einen Seite hat Google ja den Anspruch, besonders populäre und aktuelle bzw. aktualisierte Seiten im Index zu erfassen. Auf der anderen Seite sollen alte, überholte und nicht mehr aktuelle Seiten nicht mehr indexiert werden. Aus diesen Eigenschaften der Seiten ergibt sich der Crawl Bedarf. Dieser ist hoch, wenn eine Seite regelmäßig aktualisierte Inhalte bereitstellt. Er ist dagegen gering, wenn viele Seiten veraltet sind und nicht aktualisiert werden.
Aus den beiden Größen Crawl Rate und Crawl Bedarf ergibt sich also das Crawl Budget, das die Häufigkeit und Intensität des Crawling wiedergibt. Dieses wird von Google selbst als „Die Anzahl der URL, die der Google Bots crawlen kann und will“ interpretiert. Als guter „citizen of the web“ ruft der Googlebot Seiten eben nicht unnötig auf und beansprucht die Server, sondern nur, wenn Qualität und Aktualität der Einzelseiten dazu einen Grund geben. Auch außergewöhnliche Ereignisse wie etwa ein Domainwechsel oder ein Seitenumzug können Grund für intensiviertes Crawling geben.
Bad Crawlability – was den Googlebot fernhält
Während also ein gut organisierter Domainumzug oder regelmäßig aktualisierter Content das Crawl Budget erhöht, gibt es auch Faktoren, die zu einer reduzierten Crawlinghäufigkeit und damit zu einer „Bad Crawlability“ führen. Es handelt sich um -aus Sicht von Google- Qualitätsprobleme, für die Google folgende häufigste Gründe nennt:
- Facettensuche – bei einer Suche nach bestimmten Filterkriterien entstehen viele URL mit gleichem Inhalt, also duplicate content
- Session identifier – auch diese bedeuten unterschiedliche URL für ein und denselben Content, also duplicate content
- Duplicate content onsite – nicht nur aufgrund automatisierter URL-Vermehrung entstehender duplicate content, sondern auch aktiv verursachte Content Dopplung führt zu einer Verschlechterung des Crawlingbudget.
- Soft – Errors, also URL ohne Inhalt, bei denen aber vom Server fälschlicher Weise als Antwortcode „200“ an Google gesendet wird.
- Gehackte Seiten
- Inlimited Space – viele links mit weniger oder gar keiner neuen Information
- Insgesamt Inhalte mit geringer Qualität oder Spam.
Auch SEMrush zeigt in einer umfassenden und auf 450 Mio. einzelnen Seiten basierenden Studie Faktoren, die die Crawlability beeinflussen. Insbesondere Probleme mit den Sitemaps können das Crawling verlangsamen und erschweren. Wenn Sitemaps nicht aktualisiert oder gar auffindbar sind, Formatierungsfehler haben oder falsche Seiten abbilden, dann können sie ihre wichtige Funktion kaum richtig erfüllen. Diese ist, dem Googlebot die Struktur der Seite aufzuzeigen. Das Crawling wird verlangsamt und erschwert. Ähnliches gilt für eine robots.txt, bei der die Disallow-Befehle falsch programmiert sind.
Das Crawl Budget verbessern – darum lohnt es sich!
Die genannten Probleme abzustellen, um das Crawl Budget der Website zu erhöhen – das klingt nach viel Arbeit mit unsicherem Ausgang. Wäre es nicht viel einfacher und naheliegender, sich auf die wichtigen Seiten zu konzentrieren, um diese im Ranking nach vorne zu bringen? Sicher ist das auch wichtig, aber viele Fallstudien und Erfahrungen zeigen, dass die Beseitigung von URL minderer Qualität tatsächlich Sichtbarkeit und Rankings der Seiten insgesamt erhöhen. Das hat zwei einfache Gründe:
- Tatsächlich führt die Beseitigung von Seiten, die den Crawlingprozess negativ beeinflussen, dazu, dass Qualitätsseiten häufiger gecrawlt werden
- Gleichzeitig verbessert die Beseitigung von Seiten mit geringer Qualität insgesamt die Nutzererfahrung. Diese ist eines der wichtigsten Rankingkriterien und wird von Google regelmäßig gemessen. Auch hier lehren Erfahrungen aus der Praxis, dass eine Verschlankung der Seite die Rankings insgesamt verbessert.
Ein Großreinemachen auf der Seite ist also sinnvoll. Duplicate Content Seiten sollten entfernt und die Anzahl der URL im Index insgesamt reduziert werden.
Bessere Crawlability – Blick in den Maschinenraum
Aber auch andere, eher allgemein-technische Verbesserungen der Seite erhöhen die Crawlability und damit insgesamt die organische Reichweite. Solche Verbesserungen, die mit der Search Console als dem „Maschinenraum der Website“ erreicht werden können, schlägt Guy Sheetrit im SEMrush Blog vor. Es lohnt sich, seine Vorschläge zu prüfen und umzusetzen.
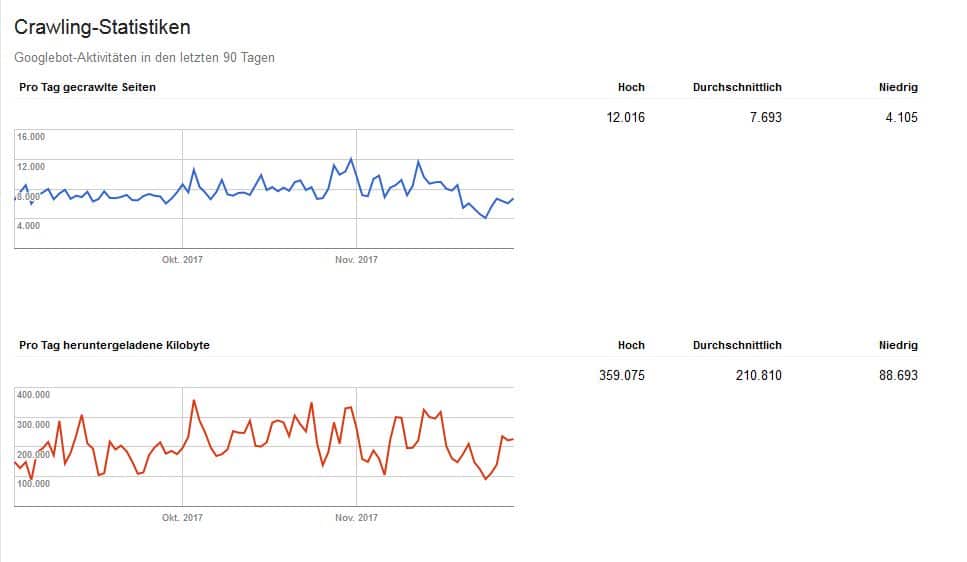
Zunächst einmal kann man nur etwas effektiv verbessern, wenn man Ergebnisse misst. Hier hilft der regelmäßige Blick in die Search Console. Dort zeigen unter dem Menuepunkt „Crawling“ die Crawling Statistiken, wieviele Seiten mit welchen Datenvolumina vom Bot erfasst wurden. Kommt es hierzu zu Verschlechterungen, ist das sicher ein Grund einzugreifen.
Ein weiterer, allgemeiner Faktor für das Crawling ist auch für die Nutzer relevant: Die Seiten- oder Ladegeschwindigkeit. Eine regelmäßige Überprüfung des Page Speed entweder über Analytics oder den Page Speed-Test gehören zum Webmaster-Pflicht Programm. Um eine Seite für das Crawling und für den Nutzer richtig flott zu machen, gilt es vor allem Bilder, JavaScript und CSS auf der Seite zu optimieren bzw. zu verschlanken. Vor allem bei Dynamischen Seiten –also solchen, die beim Upload aus mehreren Quellen zusammengestellt werden- muss die Ladegeschwindigkeit aufgrund der größeren Komplexität des Ladevorgangs eng überwacht werden.
Auch die Übersicht über die Crawling-Fehler in der Search Console sollte ernst genommen werden. Insbesondere Server-Fehler zeigen an, wenn sich der Googlebot mit Abrufen beschäftigt, die nicht zur Indexierung von Qualitäts-Seiten führen. Weiter weist Sheetrit auf AMP-Fehler als Ursache für Crawling-Probleme hin. Ist AMP nicht richtig eingebunden, dann führt das eben nicht zu der beabsichtigten Verbesserung der Performance mobiler Seiten, sondern über ein verschlechtertes Crawling und Ranking zu einer Verringerung der mobilen Reichweite.
Fazit
Wie man sieht, sind Crawlability und das Crawl Budget mehr als ein SEO Mythos, sondern eine handfeste Optimierungsaufgabe. Da sie eher abstrakt ist, gerät sie unter Umständen eher ins Hintertreffen als konkrete Onsite-Optimierungsmaßnahmen. Diese laufen allerdings ins Leere, wenn man die Qualität der Website aus der Crawlingperspektive nicht im Auge behält.